I don’t mean to bury corpse inside internet switch, but that idea would be damn cool if we could convert corpse into bits of digital information. With that we could save physical space on earth. Talk about conservation of land.
Before this, Caspershire was hosted on an unmanaged VPS (yes, all the trouble installing packages like nginx and hardening the VPS to deter breach). I had described the installation procedure when I migrated my stuff from WordPress and a full rundown on the installation process. I was happy with the solution, and my VPS was happy because the resource utilized wasn’t going to drown the system, unlike using Ghost (NodeJS) and WordPress (PHP and MySQL).
Then I decided to have some more fun with different setup. Taking care of an unmanaged VPS, although not hard, sometimes can be annoying. Another way of deploying a static content generator is to use AWS S3. Direct deployment to AWS S3 can be done locally by using s3cmd or s3_website, but changes can’t be versioned nor tracked. To enable versioning and tracking by using git, one way of doing this is to enable deployment with the help of continuous integration, CI (sometimes called continuous deployment, CD).
When I first started doing this, I deployed Caspershire to GitLab pages. When changes got pushed to Gitlab repository, the presence of a CI directive .gitlab-ci.yml would tell Gitlab CI runner module to execute necessary functions.
image: ruby:2.3
pages:
script:
- gem install jekyll
- jekyll build -d public
artifacts:
paths:
- public
only:
- master
This tells Gitlab CI to spin up a ruby container environment, then the subsequent commands instruct the CI to build the website and deploy it (the build artifacts) to Gitlab Pages. This is neat. The idea of automating build by using CI is neat. What’s even more great is that Gitlab provides Gitlab CI service for free, and it can host the generated content for free.
However, my experience got me to rely less on Gitlab. During the course of deploying Caspershire to Gitlab Pages in its early days, there were 2 times (within 3 days) the Gitlab itself was unavailable for a moment. I decided to switch from using Gitlab Pages to try GitHub + Travis CI + AWS S3 deployment strategy. The idea of doing this sounds like more work has to be done, and it is true.
For a successful deployment to S3 via build triggered on Travis, we need 3 main things, which are:
- AWS S3 bucket, together with access key and secret key.
- Account on Travis CI, SSO via GitHub.
- A directive file to instruct Travis-CI on how the build should be run, the
.travis.yml.
After signing in, we need to choose which GitHub repository to enter build process after changes being pushed.

The gear button there is clickable, and upon clicked, we will be directed to setting page.
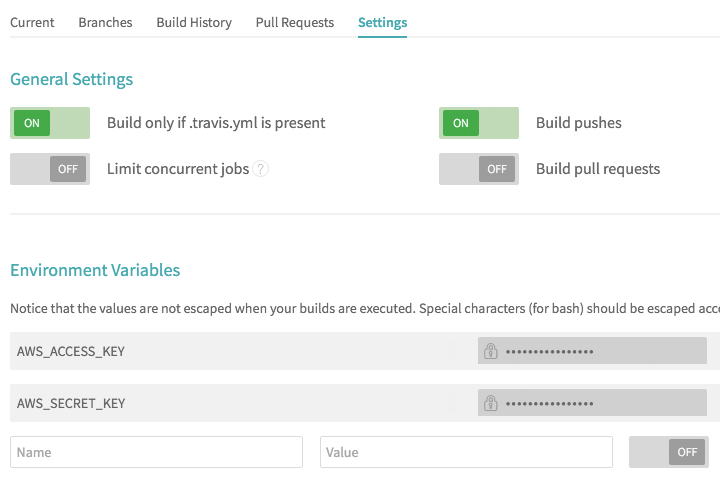
Here we can configure its behavior and also setting the environment variables. Since we are deploying to S3, we need access key for Travis CI to push the build artifacts. I will not cover here on how to obtain the key from AWS Identity and Access Management (AWS IAM).
Now let’s take a look at our .travis.yml directive.
language: ruby
rvm:
- "2.1.1"
install: gem install jekyll
branches:
only:
- public
script: jekyll build -d public
deploy:
provider: s3
access_key_id: $AWS_ACCESS_KEY
secret_access_key: $AWS_SECRET_KEY
bucket: "caspershire.net"
local_dir: public
skip_cleanup: true
acl: public_read
on:
branch: public
notifications:
email:
on_failure: always
In my case here, this instructs Travis CI to only run build process when changes being pushed to public branch. Let’s take a closer look at deploy directive. Here the access_key_id and secret_access_key take their values from environmental variables set in the Travis CI setting page. The local_dir directive describes that only build artifacts from public folder will be pushed to S3. skip_cleanup: true means that Travis CI will not delete the build artifacts (because we need to push to S3). I am not quite sure what exactly the acl directive does. Here I specify branch: public to instruct that deployment will only occur if changes are pushed from public branch of my git repository, not master or anything else. By default, Travis CI emails you if the build succeeded, but now I have it to email me notification only if there is failure.
In my case, I have 2 branches other than master branch, the draft and public branches. New articles and site-wide changes that are being worked on are committed to draft. After that those changes will be merged to master, and if everything looks great, changes will be merged to public. When the changes in public branch is pushed to GitHub, Travis CI will run the build process, and then deploy the build artifacts to S3.