I had an idea.
There was an anime that gave quite an impact to me. The anime was Dr. STONE, rated at 8.42 on MyAnimeList (MAL), which is impressive. For comparison, Attack on Titan is scored at 8.44 while Sword Art Online is scored at 7.39.
Dr. STONE is not a generic shounen anime that probably some of you are familiar with. I like it because of its emphasis on the process of scientific discovery. The show exemplifies quite nicely that science is difficult, is a communal effort, and necessary to build a strong civilization. Well, as an avid science user myself, I am biased haha.

This is the complementary article to provide insights on the process of generating data for a long-form article on my primary Caspershire blog. This blog post concerns about the process of extracting data from the show, in particular searching for specific keywords from the subtitle file. I was interested in the occurrence of certain keywords such as science for example.
Let’s have some fun!
Extracting Subtitle from MKV Video File
To extract subtitle from an MKV file, I could issue the following command with ffmpeg:
$ ffmpeg -i input_video.mkv output_subtitle.srt
To automate the whole process for all 24 episodes, I wrote this bash script.
#!/bin/bash
for i in source/*; do
name=$(basename "$i" .mkv)
printf "Extract subtitle from ${name}"
printf "\n"
ffmpeg -i "$i" -v warning "srt/${name}.srt"
printf "Done extracting from ${name}"
printf "\n"
done
I opened the output subtitle .srt file and I saw a bunch of HTML tags.
1
00:00:07,233 --> 00:00:12,303
<font face="Open Sans Semibold" size="36"><b>The strongest primate
high-schooler, Shishio Tsukasa.</b></font>
To remove the tags, I added the following line to my bash script above right after extracting the subtitle from the video to remove HTML tags with sed.
sed --expression 's/<[^>]*>//g' --in-place "srt/${name}.srt"
At first, regular expression (RegEx) did not make sense to me and I believe I am not the only person struggling to understand RegEx. So I made this illustration to help with my understanding I hope it would work for you too. The grayed out code is the command syntax for running sed: s/ to perform substitution followed by a search string (which is our RegEx code), // after the RegEx means to substitute the search string with nothing, and g at the end is to run the process globally (find every single of them).
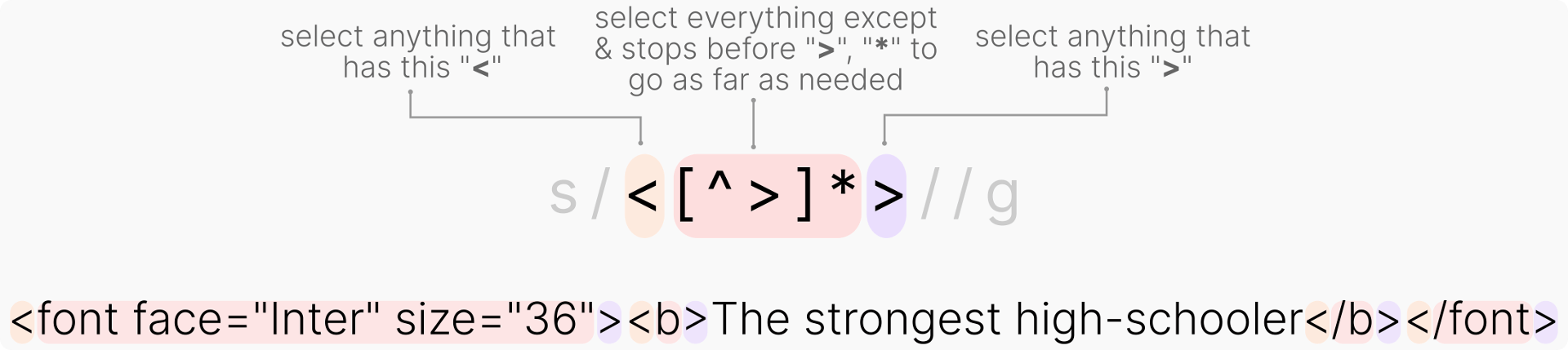
As a side note, the website RegEx 101 is a great place to write and check your RegEx code.
Now, here came the challenging part: how turn these raw input .srt subtitle files into usable data, i.e. into Pandas DataFrame object?
Turning Raw Data Into Usable Data
This part really depends on desired resolution of the data points. If I would like to know how many times the characters said the word science per episode, that would be easy. Just count the occurrence of science in an episode and call it a day.
But that would not be challenging, would it?
So I decided to make it wee bit more interesting: parse the .srt file by turning it into a Pandas DataFrame object, 1 column for the start time and another column for the text as the bare minimum. Let’s take another look at the subtitle again.
308
00:21:58,903 --> 00:22:01,613
One year since I started experimenting...
309
00:22:01,613 --> 00:22:04,133
It didn't take as long as I thought.
310
00:22:06,023 --> 00:22:07,983
It's a slow but steady effort.
This is known as the SubRip format, comprises a numeric counter, the time it should appear and disappear, the subtitle text itself, and a blank line to indicate the end of a subtitle (dialog) block. Now I know that the subtitle block is split between an empty line, I could use \n\n as the block separator.
# Read the subtitle file, then perform block split
with open('subtitle.srt') as file:
subtitle_raw = file.read()
subtitle_block = subtitle_raw.split('\n\n')
The following output was generated.

It looks very manageable now, actually. I could split 1 block into different units (i.e. numeric counter, time, and text) by using the \n as the demarcation. The problem with this approach is that some of the subtitle text have internal \n, so the text would get split. Thankfully, the string .split() method can take an argument to specify how many splits are needed.
# For example, split subtitle_block at index 0
# Only split 2 times to get 3 slices
subtitle_block[0].split('\n', 2)
# Output:
['1',
'00:00:07,783 --> 00:00:13,953',
'That day, everyone in the \nworld turned to stone.']
To remove \n in the text, I used string .replace() method
# Subtitle text at index 2, proceed directly from there to replace
# Code:
subtitle_block[0].split('\n',2)[2].replace('\n', '')
# Output:
'That day, everyone in the world turned to stone.'
To turn this into a Pandas DataFrame, I wrote this function based on the code above.
def subtitle_to_df(subtitle_file):
# Read the file
with open(subtitle_file) as file:
subtitle_raw = file.read()
subtitle_block = subtitle_raw.split('\n\n')
# Extract with list comprehension, generating nested list
line_each = [ x.split('\n', 2) for x in subtitle_block ]
# Turn nested list into Pandas DataFrame
df = pd.DataFrame(line_each, columns = ['Counter', 'Time', 'Text'])
# Drop None
df = df.dropna()
# Trime time to only take the time to appear excluding milliseconds
df['Time'] = df['Time'].apply(lambda x: x.split(',')[0])
# Remove \n in text column
df['Text'] = df['Text'].apply(lambda x: x.replace('\n', ''))
# Lowercase them all to make query easier
df['Text'] = df['Text'].apply(lambda x: x.lower())
# Return the DataFrame
return df
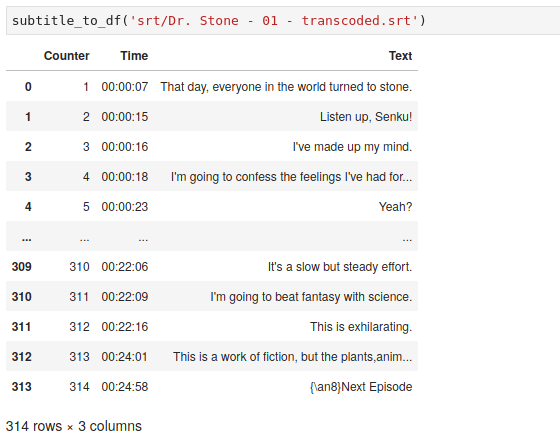
Great! Life is easier now. All of the subsequent operations would be done on this DataFrame object. For example, I would like to find dialog where the word science is mentioned, I could do it in two lines with lambda expression.
# Create new column, return "Pull" if Text contains 'science'
df['Science'] = df['Text'].apply(lambda x: 'Pull' if 'science' in x else 'Drop')
# Run query to retrieve
df.query(' Science == "Pull" ').reset_index(drop = True)
String search is case-sensitive and that is the reason why I made sure everything was in lowercase beforehand. If not, I had to run two separate queries to get the keyword Science and science. Now that the basic flow was sorted out, I switched gear and queried the keyword for the whole season 1 of the series (all 24 episodes). For this, I needed to do some walking.
One Fell Swoop
Scan a folder, return a DataFrame. Sweet.
def combinator(folder):
# Create DataFrame placeholder prior appending
df_all = pd.DataFrame()
# Create counter for episode column, start at 1
n = 1
# Read every files in 'folder'
for root, dirs, files in os.walk(folder):
# By default, things aren't sorted, so we need to sort
for file in sorted(files):
# Join root with file string
file_path = os.path.join(root, file)
# Run the function to turn raw data into df
df_each = subtitle_to_df(file_path)
# Place the episode number in new Episode column
df_each['Episode'] = n
# Increase the counter by 1
n += 1
# Append into final DataFrame
df_all = df_all.append(df_each, ignore_index = False)
# Return data with re-arranged column
return df_all[['Episode', 'Counter', 'Time', 'Text']]
The subtitle files that were extracted before with ffmpeg were placed in srt/ directory. To use the combinator() function which takes 1 argument that is the directory containing subtitle files, I ran this:
combinator('srt')
And it returned this DataFrame.
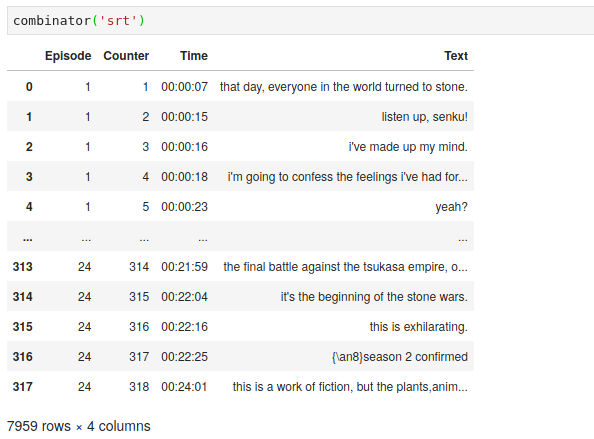
Now, everything was in a single place, I went ahead and plotted the data.
# Read files
df = combinator('srt')
# Label the data
df['Science'] = df['Text'].apply(lambda x: 'Pull' if 'science' in x else 'Drop')
# Make plot bigger
plt.figure(figsize = (8,5))
# Method chaining to query, groupby, calculate size per group, and to plot
(df
.query(' Science == "Pull" ')
.groupby('Episode')
.size()
.plot(kind = 'bar', color = 'gray')
)
# Aesthetics
plt.ylabel('Occurrence')
plt.xlabel('Episode Number')
plt.title('How Many Times "Science" is mentioned in Dr. STONE?')
plt.xticks(rotation = 'horizontal')
# Save the plot, uncomment to actually save it
#plt.savefig('Dr. STONE - first plot.png', format = 'png', dpi = 300, bbox_inches = 'tight')
# Render the plot
plt.show()
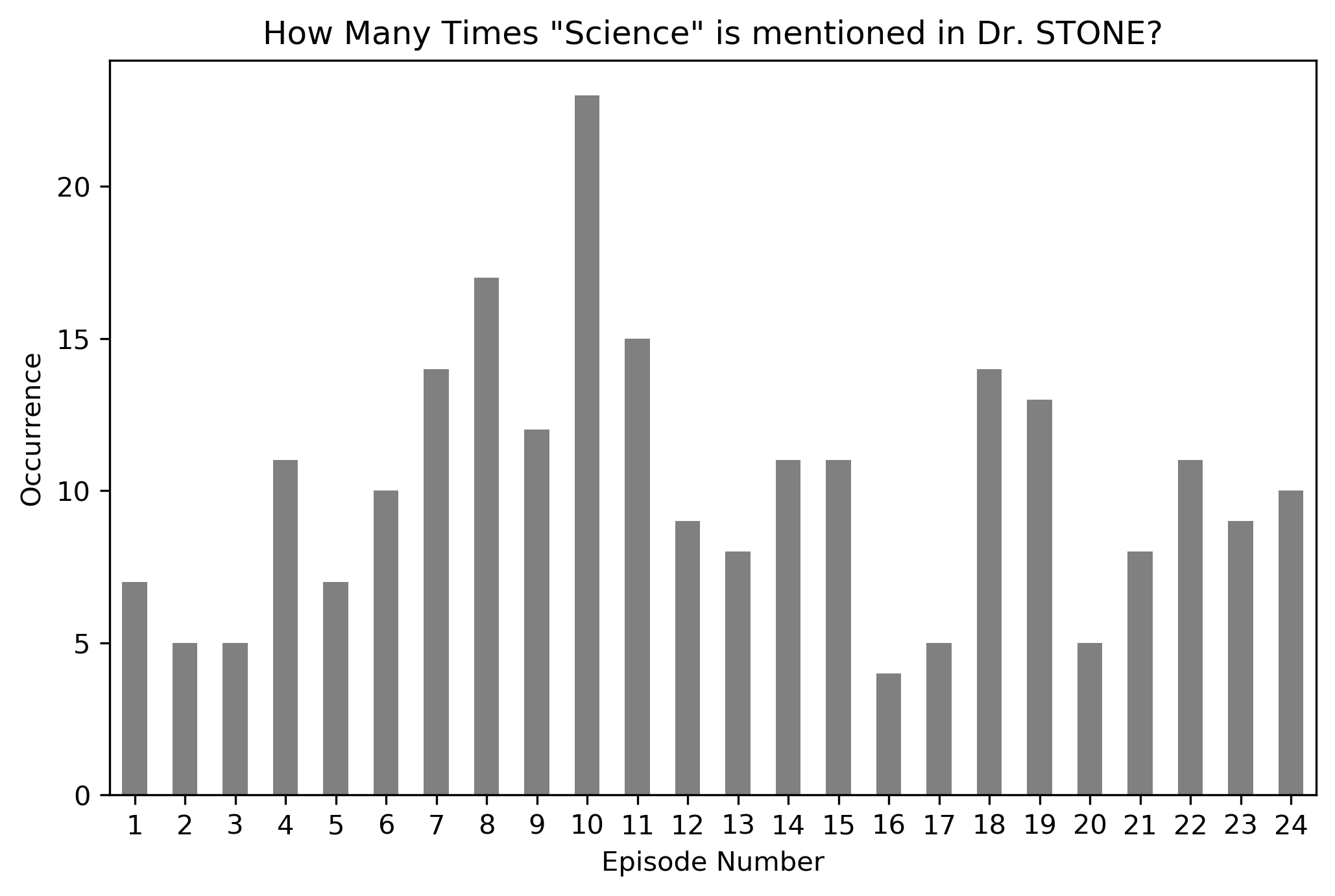
Great, I got the code to work and I got some data now. Then I got curious why episode 10 had so many mentions of science than other episodes, so I started looking around. It turned out that episode 10 was sort of a flashback episode where Senku got hooked up with science since he was very small; while everyone else was learning how to perform simple arithmetic calculations, he was already learning how to play with Einstein’s equations.
Speaking about Senku, I was interested to see if there is any correlation between the keyword Senku and Science, and tried to make a correlation plot. The code for this is available on my GitHub repo for Jupyter Notebooks: aixnr/jptrnb.
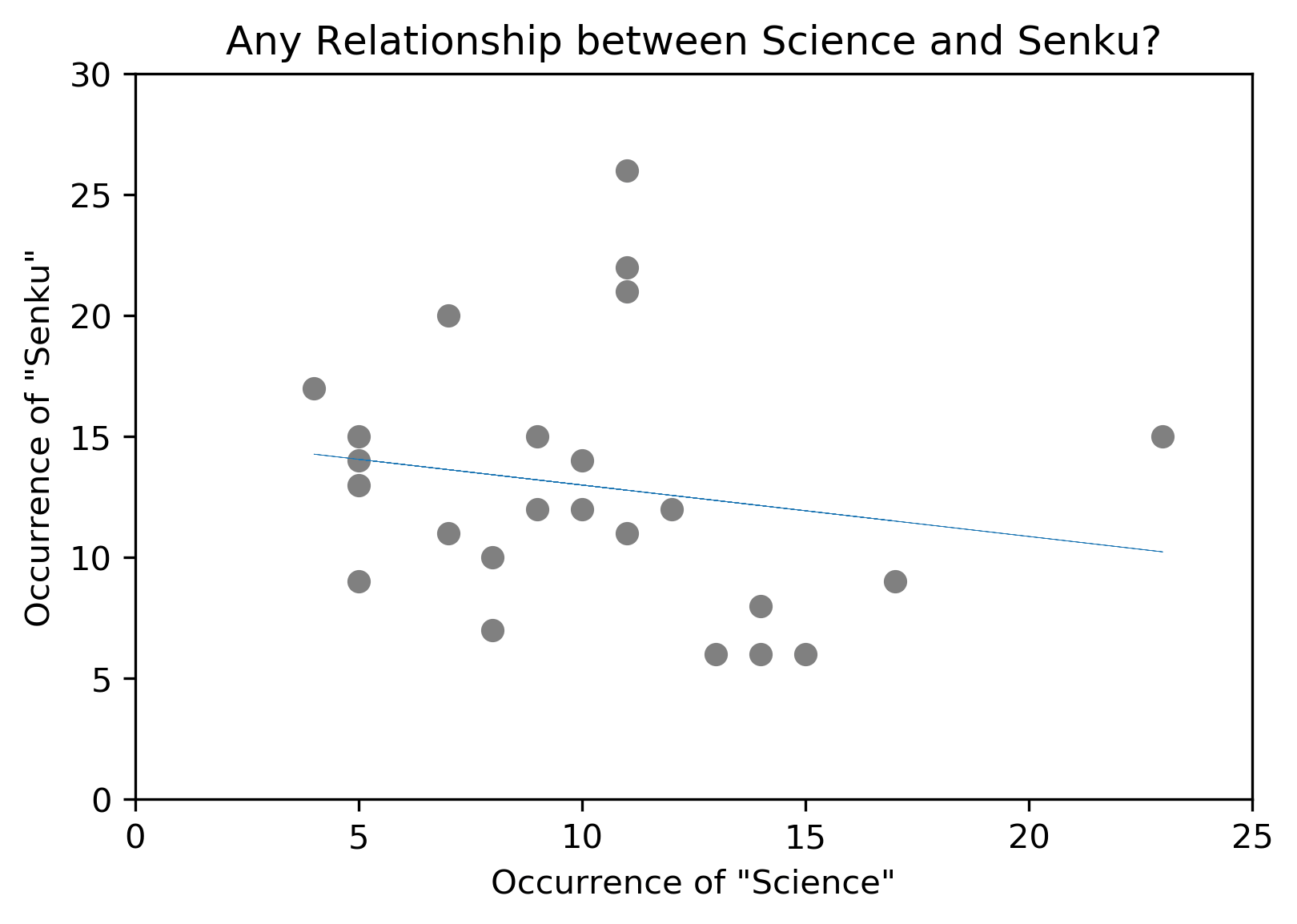
It does not seem to be any correlation between both search terms, but that is fine. On the technical side of things, I used to use Seaborn for making correlation chart, but this time I just went ahead with bare minimum: matplotlib and np.polyfit(). I think I like Seaborn’s chart better, appearance-wise.
Should I Stop Here?
Now, I decided that the party should not stop prematurely.
Since I know the time frame when science got mentioned, I decided to try to programmatically get a screenshot without using any video player, just a scripted ffmpeg approach. The base command looks like this:
$ ffmpeg -ss hh:mm:ss \
-copyts \
-i input_video.mkv \
-v warning \
-vf subtitles=subtitle.srt \
-vframes 1
screenshot.png
This process requires 3 things and returns 1 thing.
- Time in
hh:mm:ssformat. - The input video.
- A separate subtitle file.
- Returns a screenshot file in
.pngformat.
Does not seem too difficult now, does it? Adapting my previous code for extracting the subtitle file, I wrote this script, called it screenshotter.sh:
# First, extract the subtitle
ffmpeg -i "$1" -v warning "${1}.srt"
# Second, remove HTML tags
sed --expression 's/<[^>]*>//g' --in-place "${1}.srt"
# Now, take a screenshot
ffmpeg -ss "$2" -copyts -i "$1" -v warning \
-vf subtitles="${1}.srt" -vframes 1 "${1}_shot.png"
I issued the following command:
$ bash screenshotter.sh input_video.mkv 00:00:07
As a quick note, I usually added 1 or 2 more seconds from the time to appear to account for a slight delay.
Closing Words
Why did I do this?
As I said before, I was writing a long-form article on my thoughts about this anime. In the grand scheme of things, I am also interested in text mining approach because I could see how this would help me with my research. What kind of help would that be? I do not know, but must be something, right? RIGHT?